Spotter, the virtual dermatologist
Python web application developed by using Flask and Tensorflow
Skin cancer is one of the most common cancer types in the world, which can be divided into
three types: Squamous cell carcinoma (SCC), Basal cell carcinoma (BCC), and Melanoma.
SCC and BCC are the most commonly occurring forms of skin cancer. These two types of
skin cancer are often referred to as nonmelanoma skin cancers (National Cancer Institute,
2017).
In 2014 there were 131772 nonmelanoma and 15419 melanoma skin cancers registered in the
United Kingdom (UK). Malignant melanoma accounts for 2 per cent (2459) of all cancer
deaths, while nonmelanoma accounts for less than 1 per cent (781) (Cancer Research UK,
2017).
Diagnosis of skin cancer is generally carried out by a general practitioner (GP) at an initial
screening, who may refer a suspected melanoma case to a dermatologist, who will perform
minor surgical procedure called biopsy. (NHS.uk, 2017).
Benign, or noncancerous tumours develop from an irregular growth of cells that have no
purpose in the body. They are generally slow-growing and non-invasive. (Cancer Treatment
Centres of America, 2018).
A malignant or cancerous tumour, or abnormal growth of cells. Neoplasms, or the cells that
make up malignant tumours, invade nearby healthy tissue and may metastasize (spread) to
other areas of the body. (Metastasize: when cancer cells break off from the primary tumor
and travel other parts of the body through blood vessels.) (Cancer Treatment Centers of
America, 2018).
Tumours grow because of a malfunction in cells' DNA, mainly in genes that regulate cells'
ability to control their growth. Some damaged genes may also prevent bad cells from killing
themselves to make room for new, healthy cells. When the programmed cell death is altered,
the cell does not know when it's time to die and persists. If the cancerous cell learns how to
block that, and it develops the ability to proliferate, tumors grow more rapidly. Some of these
mutations lead to rapid, unchecked growth, producing tumors that may spread quickly and
damage nearby organs and tissue. Malignant cells have the ability to produce enzymes that
dissolve the native tissue. This is known as invasiveness (Cancer Treatment Centers of
America, 2018).
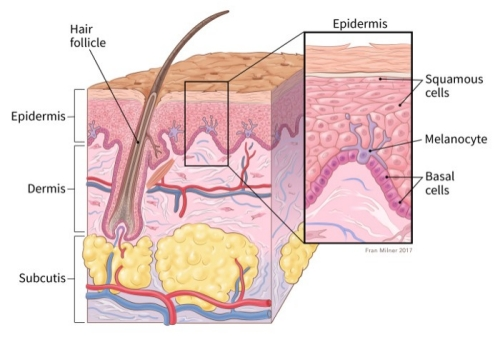
By the location of the skin cancer there are several types, but three mains are:
Squamous cell carcinoma – about 2 out of 10 skin cancers, they appear on the outer layers of
the skin. Often appear on sun-exposed areas, and they are more likely to grow into deeper
layers of the skin although this is still uncommon.
Basal cell carcinoma – The most common type of skin cancer (8 out of 10), they grow in the
lowest layer of the epidermis, called basal cell layer. Grows very slowly, however if it is
untreated, it can grow to nearby areas such as bone or other tissues beneath the skin.
Melanoma – It develops in the melanocytes, the pigment-making cells of the skin.
Melanocytes can form benign growths (moles), although melanomas are much less common
than basal -or squamous cell carcinoma, they are more likely to grow and spread if untreated.
(National Cancer Institute, 2017)
A mole (nevus) is a benign skin tumour that develops from the melanocytes, but does not
spread (National Cancer Institute, 2018).
Deep neural networks (DNN), in particular convolutional neural networks (CNN) brought
significant breakthroughs in processing and classifying images. CNNs are designed to work
with raw data come in the form of two-dimensional arrays, for example three arrays for an
image for the three colour channels (Red, Green, Blue), and the learned features in the first
layer of representation typically represents the presence or absence of edges at particularorientations
and locations in the image. The second layer typically detects motifs by spotting
particular arrangements of edges, regardless of small variations in the edge positions. The
third layer may assemble motifs into larger combinations that correspond to parts of familiar
objects, and subsequent layers would detect objects as combinations of these parts. The key
aspect of deep learning is that these layers of features are not designed by human engineers:
they are learned from data using a general-purpose learning procedure. (LeCun, Bengio and
Hinton, 2015).
Google developed it’s CNN for the ImageNet Large-Scale Visual Recognition Challenge,
that won in several categories and it has become the state-of-the-art methodology
for image recognition. The network, called Inception, was designed with computational
efficiency and practicality in mind, meaning that the inferences can be run on machines with
limited computational resources. It is twenty-two layers deep when counting the layers with
parameters and it includes around a hundred building blocks (through all layers). The final
layer is a linear which does not influence the performance however, it enables to easily retrain the model
with different classes and labels (Szegedy et al., 2015).
Transfer learning can be used to classify skin cancer images, and the trained model can
possibly perform better than dermatologists, hence it could be used as a “virtual dermatology
assistant” (Pan and Yang, 2010).
In January 2017, Stanford University used the same model to classify images of skin cancers,
and the model outperformed twenty-one board-certified dermatologists. The research
demonstrated the classification of skin diseases by using a single convolutional neural
network, using only the pixel data and the labels for training. Using the model on mobile
devices to potentially extend the reach of dermatologists outside of the clinics, however such
an application backed up with scientific model evaluation was never delivered. (Esteva et al.,
2017).
The main objective of this project was to develop an application that is capable of differentiating between melanoma and nevus skin diseases with a reasonably high accuracy. The project was divided into two deliverables:
The biggest challenge was to find enough publicly available data. In 2018 in Stanford University’s research, a dermatologist-labelled dataset of 129,450 clinical images was used, including 3,374 dermoscopy images. These images were acquired from three different sources: the ISIC Dermoscopic Archive, the Edinburgh Dermofit Library and data directly from Stanford Hospital. The hospital’s and the Edinburgh Dermofit Library’s data were not accessible for this project, however the ISIC archive currently provided eleven different data sets with 23906 melanocytic lesion images that were biopsy-proven.
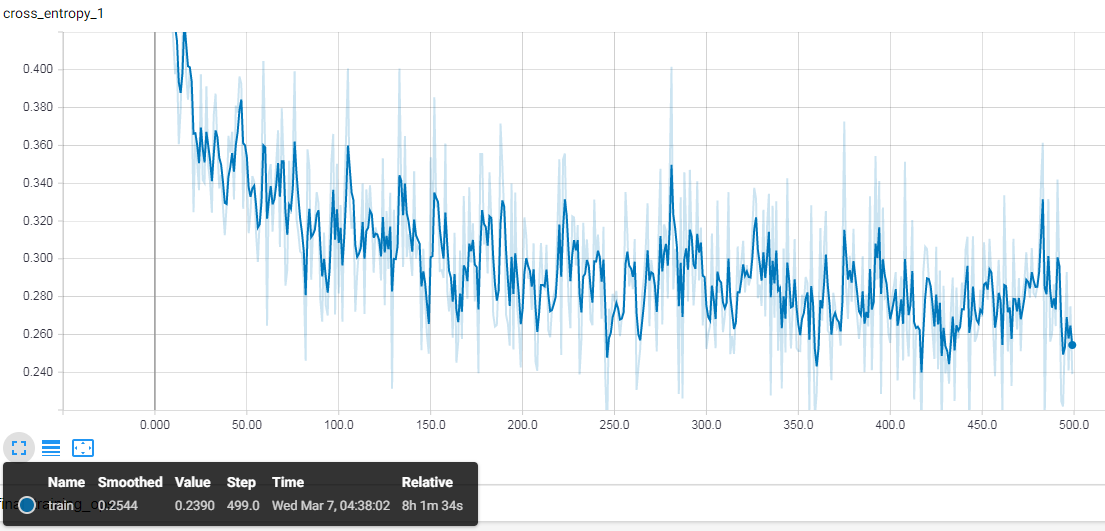
During the training the cross entropy, the training accuracy and the validation accuracy were recorded after each training episode. The training accuracy showed what percent of the images (used during the training) were correctly labelled after each episode and the validation accuracy showed what percent of the randomly selected images (not included in the training set) were labelled correctly after each episode. Cross entropy is a loss function and it was used to measure the error between the computed outputs and the desired target outputs of the training data. It was calculated after each episode and the objective of the training was to make the loss as small as possible.
After each model training the cross entropy and the validation accuracy were observed to decide how many episodes the next training should have. If the validation accuracy did not improve and the loss did not decrease significantly, the model did not learn new features, therefore having more episodes were pointless. The evaluation of the model was performed by running predictions on a test dataset which includes images that were not used during the training. The four outcomes for each image are:
These outcomes were formulated in a 2 by 2 confusion matrix and from the matrix the recall, fall-out,
miss rate and specificity were calculated. Finally, the recall and fall-out were used to draw a ROC-curve
and decide which model has the best probability for giving an informed decision between the two
classes.
Point above the line represents good classification results or at least better than random points below
represent bad results (worse than random) however, bad results can easily be converted to good by inverting
the results.
Several models were trained to find the correct hyperparameters. During the training, the models’ accuracy
was recorded after
every step (episode), and after every tenth steps the model was validated with randomly selected 300 images.
The loss function
(cross entropy) was recorded in the same way, after every step for the training and after every tenth step
for the validation.
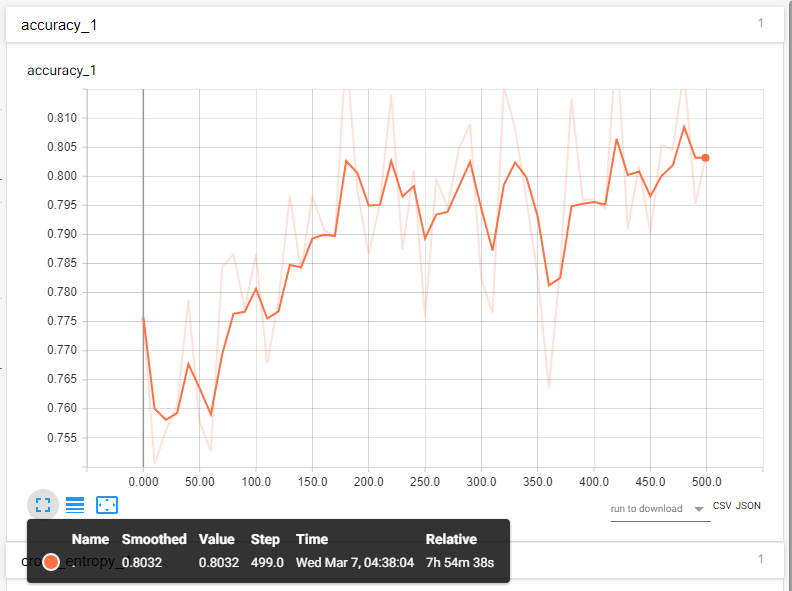
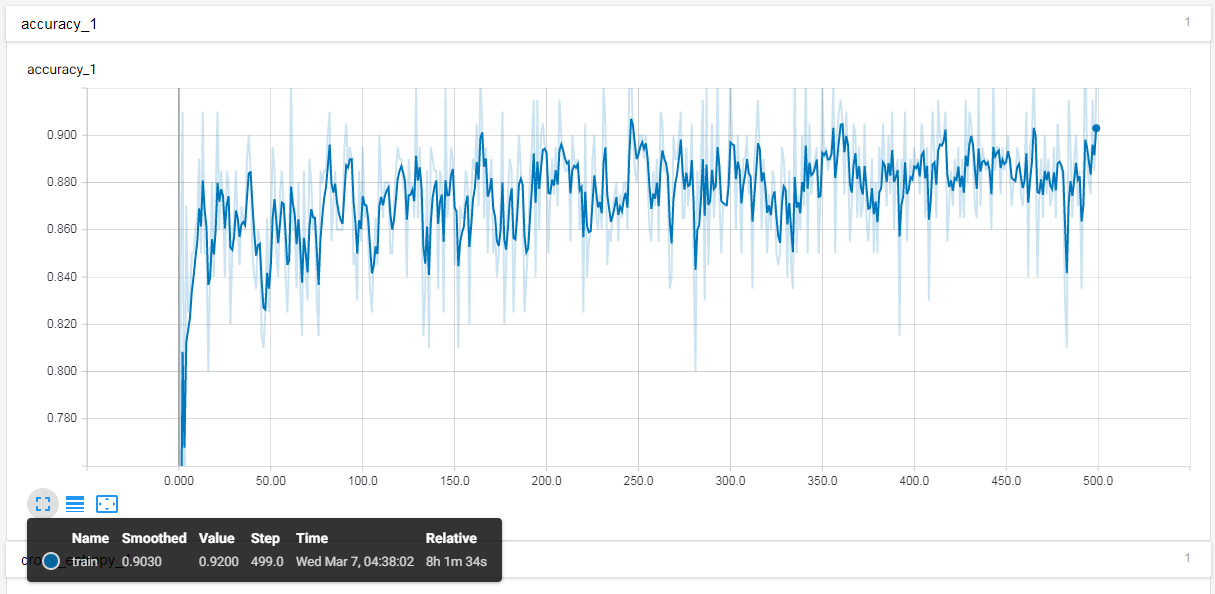
For each model, two graphs were generated via TensorBoard that showed the accuracies and the cross entropy
as a function of steps.
To validate the models, the recall, the specificity, the miss rate, the fall-out and the accuracy was
calculated by using a
test set with 2104 (10%) images which were not used during the training.
The first model was trained without using and further transformations on the images, such as random crop, random brightness or random scale with 400 training steps while using 1000 images at each step. Since accuracy during the training did not increased significantly and the error rate did not decrease after about 200 steps, the number of steps were reduced during the next trainings. The model’s accuracy was 79.5% with 0.914 recall (Table 5).
In the second training to make the model more flexible, the image size was randomly increased or decreased by 10%, and the brightness with 15% and the training steps were reduced to 200. During the last 60 steps, some overfitting was observer (training accuracy was higher than the validation accuracy), meaning the model learnt the details of the images used during the steps rather than general features. However, the model’s accuracy (validated on the held-out set) was higher than the first model’s, while the recall dropped slightly (Table 6).
For the third training, the learning rate was increased, while the rest of the parameters were not changed. The overfitting was more significant compared to the previous training, indicating that 0.2 learning rate was too high (Appendix O), the model might have learnt faster (training accuracy) however it only learnt the particular images features rather than generic features. The overall accuracy also dropped while recall increased slightly
In the final training the learning rate was set back to 0.1, but the training batch size was increased to 2500 images). The training and validation accuracy were very similar during the training except a spike at the 190th step where the validation accuracy dropped under the training with about 3% which implies high overfitting. The final results of the model, however still came out as the second-best model when the accuracy and recall was considered (Table 8).
By purely looking at the accuracy, the second model (melanoma_nevus_m2) was the best with 0.80370724 accuracy, however, given the problem recall had to be considered. High recall means that the model performs well when it receives a melanoma sample. Some drop in the overall accuracy is acceptable to ensure that most of the patients who have skin cancer are not told that it is a non-melanoma skin disease.
The majority of the code was written in python, using Tensorflow for the model training, OpenCV
for image pre-processing, and
Flask for the back-end web-development. The metadata of the images was stored in Microsoft SQL database and
the front-end was built with
Html, CSS and Bootstrap 3.
As demonstrated in the research by Stanford university, Google’s InceptionV3 model can be retrained for recognising skin diseases directly from photos. The model can be used to create web-applications which run on mobile devices, which could potentially be used as a virtual dermatologist to assist healthcare professionals. With the availability of fast GPUs and their considerably low price and with the available open datasets, a model such as the InceptionV3 can be retrained by anybody with programming experience and the necessary hardware. The output of this project was differentiating between two classes, melanoma and nevus and resulted in a model with 80% accuracy which is significantly lower than the result from Stanford University. This could be because of the smaller dataset, and the differences in the methodology. Even in Stanford’s research, when the classification was done with one thousand different skin diseases, the accuracy dropped significantly, proving that the available data is a very important factor in supervised learning. Nevertheless, new datasets are made available every day for example at the beginning of this project the ISIC dataset included around thirteen thousand images, but at the time of writing this report there were 23906 images available, and as more data are becoming available, the model can be retrained to increase its the performance.
We were very pleased with the project. I thought it was an exemplary UG project, because it addressed a number of aspects of computer science and software development, had an innovative aspect and created some real value.